
El modelo de Von Neumann, también conocido como arquitectura de Von Neumann o arquitectura Princeton, es un diseño conceptual de computadoras propuesto en 1945 por el matemático y físico John von Neumann y sus colaboradores. Se trata de una arquitectura de programa almacenado que describe cómo un ordenador digital puede almacenar tanto las instrucciones del programa como los datos en una memoria de acceso aleatorio (RAM), compartiendo ambos el mismo espacio de memoria. Este modelo revolucionario define los componentes fundamentales de un computador – unidad de procesamiento, unidad de control, memoria, dispositivos de entrada/salida – y cómo se interconectan mediante buses, sentando las bases de prácticamente todas las computadoras modernas. Gracias a la arquitectura de Von Neumann, fue posible pasar de las primeras máquinas de programa fijo (como la ENIAC, que requería re-cablear físicamente para cambiar de programa) a sistemas flexibles donde para reprogramar basta con cargar un nuevo conjunto de instrucciones en memoria. En otras palabras, el modelo de Von Neumann aportó simplicidad de diseño y flexibilidad, permitiendo que un mismo hardware ejecute distintos programas almacenados en memoria.
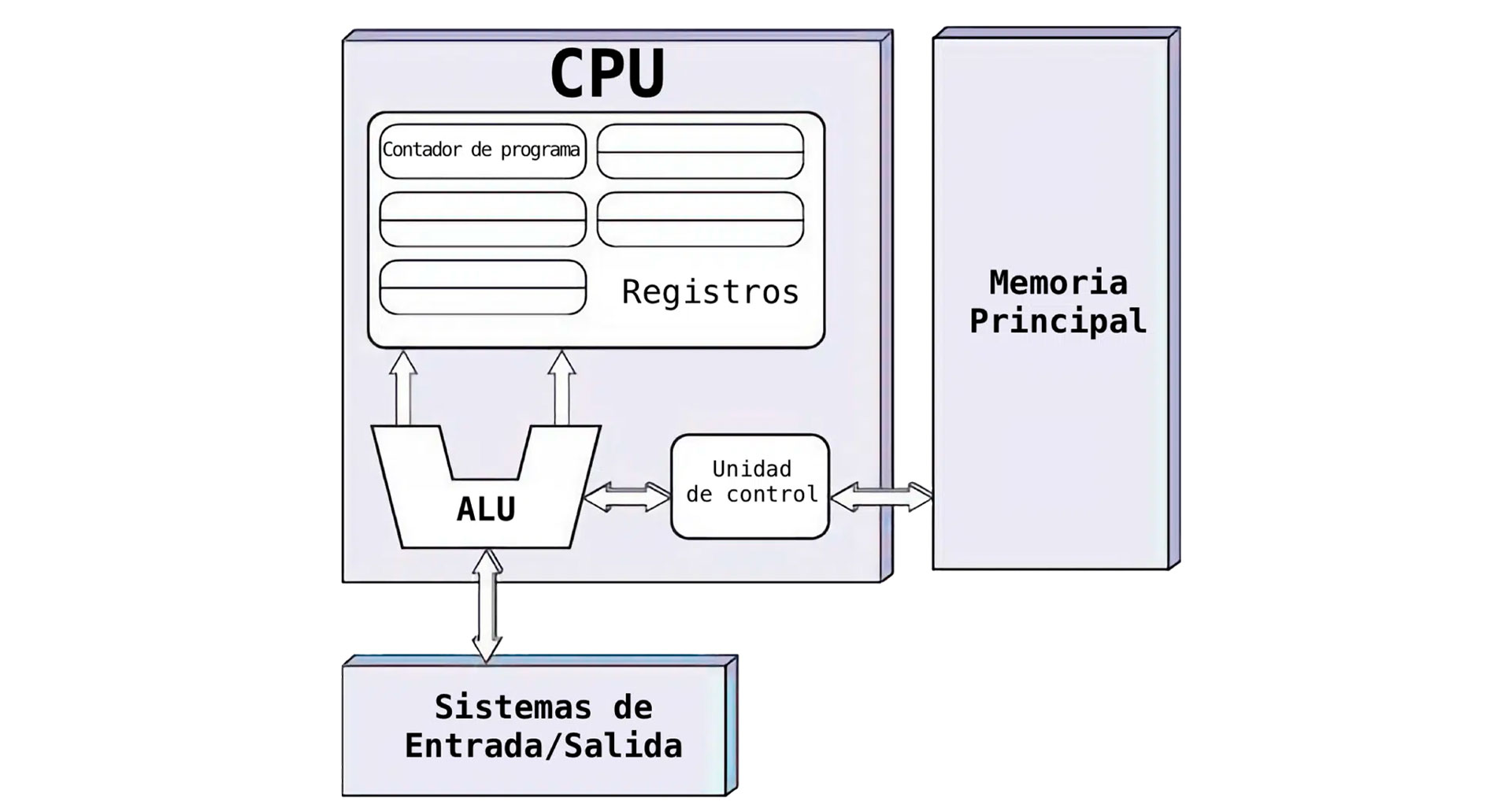
Figura: Diagrama de la arquitectura Von Neumann. En esta arquitectura, la CPU (compuesta por la unidad aritmético-lógica, registros y unidad de control) se conecta a una memoria principal y a los dispositivos de entrada/salida a través de un bus común, por donde fluyen tanto las instrucciones como los datos. Este diseño unificado simplifica la construcción del computador, pero conlleva el “cuello de botella” típico de Von Neumann: al compartir un solo canal, la CPU no puede acceder simultáneamente a las instrucciones y a los datos.
Partes del modelo de Von Neumann
El modelo de Von Neumann se compone de la CPU, la memoria principal, la unidad de control, los buses de comunicación y los dispositivos de entrada y salida. Estas partes trabajan en conjunto para permitir la ejecución de programas almacenados.
El modelo de Von Neumann organiza el computador en varios componentes fundamentales que trabajan en conjunto:
- Unidad Central de Proceso (CPU): Es el corazón del sistema. La CPU incluye a su vez:
- Unidad Aritmético-Lógica (ALU), encargada de realizar las operaciones matemáticas básicas (suma, resta, etc.) y operaciones lógicas (AND, OR, NOT).
- Unidad de Control, que busca las instrucciones en la memoria, las decodifica y coordina su ejecución secuencial.
- Registros del procesador, pequeñas memorias internas muy rápidas donde se almacenan temporalmente datos e instrucciones durante el procesamiento. Los registros actúan como almacenamiento intermedio para acelerar el acceso a los datos más usados por la ALU y la unidad de control.
- Memoria principal: Es la memoria de acceso aleatorio (RAM) donde se almacenan temporalmente tanto las instrucciones del programa en ejecución como los datos con los que trabaja dicho programa. La memoria está organizada en celdas o direcciones únicas, lo que permite acceder a cualquier posición de forma directa y rápida. En el modelo Von Neumann, esta misma memoria contiene indistintamente instrucciones y datos, sin distinción en su estructura física.
- Buses del sistema: Son los canales de comunicación (conjuntos de líneas conductoras) que interconectan la CPU, la memoria y los periféricos de entrada/salida. Habitualmente se componen de un bus de datos (que transporta los datos en sí), un bus de direcciones (para indicar la dirección de memoria a acceder) y un bus de control (para señales de control y sincronización). En la arquitectura Von Neumann clásica, todos estos buses conforman un único canal compartido para transferir tanto datos como instrucciones entre la CPU y la memoria.
- Sistema de Entrada/Salida (E/S): Son los dispositivos periféricos y sus controladores, que permiten la comunicación del computador con el exterior. Incluye unidades de entrada (como teclado, ratón, micrófono) para introducir datos al sistema, y unidades de salida (pantalla, impresora, altavoces) para obtener resultados. La arquitectura Von Neumann contempla estos dispositivos conectados a la CPU y la memoria a través del bus del sistema, mediante interfaces que gestionan la transferencia de datos entre los periféricos y la memoria.
Estos componentes trabajan de forma coordinada: la CPU lee instrucciones desde la memoria y las ejecuta, utilizando los buses para transportar instrucciones y datos entre memoria, procesador y E/S. Este diseño unificado fue la base de la gran mayoría de ordenadores construidos desde mediados del siglo XX hasta la actualidad, debido a su simplicidad y eficacia para la computación general.
El cuello de botella de Von Neumann
Si bien el modelo de Von Neumann supuso un avance enorme, también introdujo una limitación conocida como el “cuello de botella de Von Neumann”. Este problema deriva del hecho de que procesador y memoria comparten el mismo bus para sus comunicaciones. En un ordenador Von Neumann, la CPU no puede buscar (fetch) una nueva instrucción en memoria al mismo tiempo que realiza una operación de lectura/escritura de datos, ya que ambas transacciones deben usar el único bus disponible. En otras palabras, las transferencias de datos e instrucciones no pueden superponerse, forzando a la CPU a esperar que termine una operación para iniciar la siguiente. Esta dependencia secuencial impone un límite a la tasa de transferencia de información entre la CPU y la memoria, restringiendo el rendimiento global del sistema. El resultado es que, por más rápido que sea el procesador, su desempeño queda frenado por la velocidad a la que puede recibir instrucciones y datos de la memoria.
¿Por qué ocurre el cuello de botella?
Varios factores inherentes a la arquitectura Von Neumann contribuyen a este cuello de botella:
- Datos e instrucciones en la misma ruta: Al almacenarse en la misma memoria y viajar por el mismo bus, las instrucciones de un programa y los datos compiten por el ancho de banda. El procesador no puede acceder a una instrucción a la vez que accede a datos, ya que ambos requieren el uso del bus compartido. Esto impide aprovechar posibles solapamientos en la ejecución (por ejemplo, no se puede ir cargando la siguiente instrucción mientras se procesan datos de la instrucción actual, como sí ocurriría en arquitecturas con buses separados).
- Diferencia de velocidad entre CPU y memoria: Los procesadores modernos operan a velocidades muy superiores a las de la memoria principal. La CPU puede ejecutar millones de operaciones por segundo, pero la memoria tarda comparativamente mucho más en entregar datos. Este desajuste hace que la CPU pase ciclos inactiva esperando a que lleguen nuevas instrucciones o datos desde la RAM. En esencia, el rendimiento queda limitado por el componente más lento (la memoria), independientemente de la rapidez del procesador.
- Procesamiento estrictamente secuencial: El modelo Von Neumann ejecuta las instrucciones una tras otra, siguiendo la secuencia dictada por el programa (a través del contador de programa). No existe de base la posibilidad de ejecutar múltiples instrucciones simultáneamente. Esta dependencia secuencial significa que incluso en tareas que podrían paralelizarse, la arquitectura original no lo permite, reduciendo la eficiencia en cargas de trabajo que se beneficiarían del paralelo.
- Un único bus para todo: La presencia de un solo canal de datos y direcciones limita físicamente la cantidad de información que se puede transferir en un instante dado. El bus tiene un cierto ancho (por ejemplo 8, 16, 32 bits, etc.), lo que fija el tamaño de los datos o instrucciones que se pueden mover de una vez. Si una instrucción o dato es más grande que el ancho del bus, la CPU tendrá que hacer múltiples accesos a memoria para cargar esa instrucción o dato completo, añadiendo demoras adicionales. Además, al usarse el mismo bus tanto para leer como para escribir, las operaciones de E/S también comparten ese canal, pudiendo bloquear temporalmente otras transferencias.
En conjunto, estos factores crean el efecto de embudo o cuello de botella: por muy poderoso que sea el procesador, su rendimiento se verá limitado por la velocidad del flujo de información entre él y la memoria. Por ejemplo, si la memoria solo puede entregar X datos por segundo, la CPU no podrá procesar más allá de esa tasa sin quedarse esperando. Este cuello de botella de Von Neumann es frecuentemente señalado como la principal limitación de la arquitectura y un desafío en los diseños de computadores actuales.
Consecuencias en el rendimiento
El impacto del cuello de botella de Von Neumann se manifiesta en varios aspectos:
- Rendimiento limitado del sistema: La velocidad global del computador queda condicionada por la lenta comunicación con la memoria. Aunque la CPU tenga un alto potencial de cálculo, solo puede trabajar tan rápido como le lleguen las instrucciones y datos desde la RAM. En términos de tasa de transferencia, el bus compartido actúa como un límite superior – un estrechamiento que impide aprovechar al 100% la capacidad del procesador. Esto se traduce en tiempos de espera y en un throughput menor al teóricamente posible.
- Uso ineficiente de la CPU: Dado que el procesador pasa buena parte del tiempo esperando datos o instrucciones, se desaprovecha su potencia. El CPU podría realizar más operaciones, pero no tiene con qué trabajar hasta que la memoria responda. Este ocio forzado de la CPU reduce la eficiencia y rendimiento por ciclo de reloj. En términos prácticos, significa que gran parte de los transistores y unidades funcionales del procesador están inactivos durante muchos ciclos, lo que es ineficiente energéticamente y en desempeño. El sistema en conjunto parece lento porque su componente más rápido (CPU) está frenado por el más lento (memoria).
Soluciones para mitigar el cuello de botella
A lo largo de las décadas, la ingeniería de computadores ha desarrollado varias técnicas y mejoras arquitectónicas para paliar el cuello de botella de Von Neumann. Algunas de las más importantes son:
- Memoria caché: Es una memoria pequeña y ultrarrápida situada entre la CPU y la memoria principal (RAM). La caché almacena temporalmente los datos e instrucciones más usados recientemente, de modo que el procesador pueda acceder a ellos mucho más rápido que si tuviera que ir hasta la RAM. Al servirse de la caché, se reduce la frecuencia con que la CPU necesita comunicarse con la memoria lenta, aliviando el cuello de botella. En esencia, la caché actúa como un buffer que amortigua la diferencia de velocidad entre CPU y RAM, aprovechando la localidad de referencia.
- Ejecución pipeline (tubería de instrucciones): Consiste en descomponer la ejecución de instrucciones en etapas y superponerlas en el tiempo, similar a una línea de montaje. Mientras una instrucción está en la fase de ejecución, la CPU ya puede ir cargando y decodificando la siguiente instrucción en paralelo. Esta técnica permite tener varias instrucciones en curso simultáneamente, aumentando el aprovechamiento de la CPU. El pipeline no elimina el cuello de botella del bus, pero reduce la ociosidad de la CPU al mantenerla ocupada con un flujo constante de instrucciones.
- Procesamiento en paralelo y multinúcleo: Otra solución es duplicar o multiplicar los recursos de procesamiento. Los procesadores multinúcleo incorporan varias unidades de CPU en el mismo chip, de forma que puedan ejecutar múltiples hilos o programas a la vez. Asimismo, técnicas de paralelismo interno permiten realizar más de una operación por ciclo de reloj. Aunque todas las unidades siguen accediendo a la misma memoria principal, al distribuir la carga entre varios núcleos se mitiga el efecto del cuello de botella para cada núcleo individual.
- Arquitectura Harvard (memoria separada): Es una arquitectura alternativa en la cual se usan memorias físicamente separadas para las instrucciones y para los datos, cada una con su propio bus independiente. De este modo, la CPU puede leer simultáneamente una instrucción de la memoria de programa mientras, en paralelo, escribe o lee datos desde la memoria de datos. Esta separación elimina de raíz el cuello de botella típico de Von Neumann.
Gracias a estas optimizaciones, la arquitectura de Von Neumann ha logrado mantenerse vigente adaptándose a las crecientes demandas de rendimiento de la computación moderna. En la práctica, la mayoría de las computadoras actuales son una mezcla de la simplicidad Von Neumann con mejoras tipo Harvard y otras innovaciones.
Ventajas del modelo de Von Neumann
A pesar de sus limitaciones, el modelo de Von Neumann presenta varias ventajas clave que explican su predominio histórico:
- Diseño simple y uniforme: Al almacenar programas y datos en la misma memoria, la arquitectura es más sencilla de diseñar e implementar que otras alternativas con memorias separadas. Toda la lógica de la máquina puede centrarse en un único espacio de direcciones y un conjunto unificado de buses, lo que simplifica el hardware y la gestión de la memoria.
- Flexibilidad y facilidad de programación: La idea del programa almacenado supuso una revolución: en lugar de reconfigurar físicamente el hardware para cambiar la tarea de la máquina, bastaba con cargar un programa diferente en memoria. Esto significa que una computadora Von Neumann puede realizar cualquier tarea (dentro de sus capacidades) simplemente cambiando el software.
- Base de la computación moderna: El modelo de Von Neumann se convirtió en el esquema fundamental para casi todas las computadoras construidas desde mediados del siglo XX. Dispositivos actuales como PCs, servidores e incluso smartphones siguen, en esencia, la arquitectura Von Neumann mejorada.
Limitaciones del modelo de Von Neumann
La arquitectura Von Neumann presenta importantes limitaciones frente a las necesidades de la computación actual:
- Cuello de botella entre CPU y memoria: El rendimiento queda limitado por la velocidad de intercambio de información por el bus único. Aunque los procesadores han incrementado exponencialmente su velocidad, la memoria y el bus no han podido seguir ese ritmo, creando un desbalance.
- Dependencia de ejecución secuencial: El modelo Von Neumann puro ejecuta solo un hilo de instrucciones a la vez, lo que no aprovecha las ventajas del procesamiento paralelo. Aunque se han introducido tuberías y múltiples núcleos, la arquitectura original no estaba pensada para concurrencia masiva.
- No optimizada para ciertos usos modernos: Aplicaciones como el procesamiento digital de señales, gráficos de alto rendimiento o computación científica intensiva pueden tropezar con las limitaciones de Von Neumann. Por ello han surgido arquitecturas alternativas como la Harvard y diseños no-Von Neumann (flujo de datos, neuromórficos, cuánticos).
En resumen, el modelo de Von Neumann fue un hito fundamental que definió la informática tal como la conocemos. Su enfoque de programa almacenado y diseño simplificado permitió el auge de los computadores de propósito general y sigue siendo el marco de referencia para la mayoría de las arquitecturas. Sin embargo, también impuso el bien conocido cuello de botella que limita el rendimiento. La industria ha respondido incorporando mejoras y evolucionando hacia arquitecturas híbridas y alternativas para mitigar sus limitaciones. Aun con sus defectos, la arquitectura Von Neumann se mantiene como piedra angular de los sistemas computacionales, equilibrando su simplicidad original con las innovaciones necesarias para seguir vigente en la era de la alta velocidad y el paralelismo.
Referencias
- J. von Neumann et al., “First Draft of a Report on the EDVAC” (1945) – Informe pionero que describe la arquitectura de programa almacenado. es.wikipedia.org
- Emilio Orts, Tema 2 – Elementos funcionales de un ordenador digital (Apuntes oposiciones SAI) – Sección 2.4 sobre limitaciones y mejoras de la arquitectura Von Neumann. eorts.com
- Oscar Rosas, Compilando Conocimiento – Artículo “Arquitecturas Von-Neumann vs Harvard” con explicación del bus único y cuello de botella. compilandoconocimiento.com
- Javier Izquierdo, Weblinus – Artículo “Arquitectura Von Neumann y arquitectura Harvard” destacando limitaciones de Von Neumann y ventajas de Harvard. weblinus.com
- Wikipedia (es), “Arquitectura de Von Neumann” – Definición y contexto histórico de la arquitectura Von Neumann. es.wikipedia.org
Preguntas frecuentes
¿Qué es el modelo de Von Neumann y cómo funciona?
Es una arquitectura de programa almacenado donde datos e instrucciones comparten la misma memoria y viajan por un bus común.
¿Cuáles son las partes del modelo de Von Neumann?
Incluye CPU, memoria principal, unidad de control, buses y dispositivos de entrada/salida.
¿Qué es el cuello de botella de Von Neumann?
Es la limitación que surge al compartir un único bus para datos e instrucciones, lo que puede ralentizar el rendimiento del sistema.



¡Excelente artículo! La explicación del modelo de Von Neumann es clara y fácil de seguir. Me gustó cómo conectaste los conceptos fundamentales con aplicaciones modernas. Aporta mucho valor a quienes estamos aprendiendo sobre arquitectura de computadoras. ¡Gracias por compartir!
Excelente explicación sobre el modelo de Von Neumann. Me pareció muy interesante cómo desglosas cada componente y sus funciones. Definitivamente me ayudó a entender mejor la arquitectura básica de las computadoras. ¡Gracias por compartir!
¡Excelente explicación sobre el modelo de Von Neumann! Me pareció interesante cómo detallas los componentes y sus funciones. Definitivamente ayuda a entender la base de la arquitectura de computadores y por qué sigue siendo relevante hoy en día. ¡Gracias por compartir!
¡Excelente explicación sobre el modelo de Von Neumann! Me parece fascinante cómo su estructura y componentes han influido en la arquitectura de computadoras modernas. Las ventajas que mencionas son muy relevantes y ayudan a entender por qué este modelo sigue siendo fundamental en la informática actual. Gracias por el contenido claro y conciso.