Anteriormente hicimos nuestra propia herramienta en PHP para la recolección de información de canales RSS. El script está funcionando muy bien a día de hoy tras este tiempo de prueba. Hicimos unos pequeños ajustes y ahora nos da las noticias exclusivamente a ciertas horas, lo cual hace que nos vaya genial y sea muy práctica.
Pero ahora lo que necesitábamos era algo parecido para usuarios de Twitter. Es por ello por lo que hemos realizado esta herramienta con Python que recoge información de una serie de cuentas (enlace a GitHub al final). Qué hashtags utilizan más, a quién hacen RT o con qué usuarios interactúan más. También nos saca información sobre los últimos tuits. Dependiendo de los parámetros que asignemos a esta herramienta nos dará más o menos información. Es muy útil para labores de ciberinteligencia porqué nos puede proporcionar información sobre diferentes usuarios a monitorizar. Una de las principales características que le hemos dado a esta herramienta es la capacidad de saber si hay un nuevo tuit puesto por un usuario o no, y, si ese tuit es nuevo, nos manda una alerta al móvil por correo electrónico. Así siempre mantendremos bajo seguimiento las diferentes cuentas de interés.
Este script se puede ampliar de diferentes maneras y se le pueden asignar numerosas utilidades, monitorización de hashtags sobre eventos de interés, monitorización de palabras clave, etc.
Otro uso para este script podría ser el de hacer un bot para Twitter, ya tenemos prácticamente todo hecho, solo necesitaríamos que subiese nuevos tuits o que retuitease. Pero eso lo dejamos para otra ocasión.
Información que podemos recolectar actualmente
- Nombre.
- Nombre de usuario.
- Descripción de la cuenta.
- Número de usuarios seguidos.
- Número de usuarios seguidores.
- Tiempo que lleva la cuenta activa en días.
- El porcentaje de tuits diarios.
- Los hashtags más utilizados (con sus respectivos nombres).
- Las menciones de otros usuarios, y las veces que los han mencionado.
- Sacaremos los últimos 5 tuits, por ejemplo, este número se puede variar.
- Finalmente nos dirá el número de tuits procesados para llevar a cabo esa tarea (el número de días a los que se remontará el script para revisar los tweets es variable y se puede poner de forma manual).
El objetivo principal es testear las opciones que permite Twitter hacer, para poder comprender su funcionamiento y posteriormente hacer un programa más grande que nos de una motorización mayor. Lo que consideramos más importante es la actualización continua de la monitorización y el hecho de que pueda darnos información en tiempo real sobre los últimos tuits de ciertos usuarios. Así la motorización de ciertas cuentas será más fácil.
Posible actualización que realizaremos: monitorización de hashtags. La monitorización de hashtags es imprescindible para conocer más sobre eventos que están sucediendo en tiempo real.
Requisitos para su funcionamiento
Para la realización de este script de recolección de información en Twitter hemos hecho uso de Python, un servidor VPS para hacer que los scripts estén siempre en funcionamiento, CRON para hacer que se repita la ejecución del script cada X tiempo y un correo electrónico para realizar los envíos por correo electrónico.
El servidor VPS es totalmente prescindible. Podremos instalar un servidor en una raspberry pi o en un ordenador que tengamos por casa sin ningún tipo de problema.
Con respecto a los requisitos de Python hemos utilizado la librería Tweepy para acortar el proceso y hacerlo de manera más rápida. Para usar Tweepy hemos necesitado la API de Twitter que ya usamos en su momento en el artículo de OSINT en el cual hablamos de la herramienta de Vicente Aguilera con su programa de recolección de información en Twitter “Tinfoleak“.
Recomendación final antes de comenzar a ver su creación. Hemos observado que la API de Twitter permite hacer un número de peticiones limitado. Es decir, el script no puede ejecturase muchas veces seguidas ni pueden ponerse muchos usuarios puesto que Twitter nos cortará el acceso. Actualmente lo tenemos funcionando con 18 usuarios y la verdad que funciona perfectamente, pero si que se hace tediosos cuando hay que actualizar partes del script y comprobar que funciona todo.
Creando el script de recolección de información en Twitter
Vamos a ver paso a paso cómo hemos creado el script. Nuestra intención es que se comprenda el funcionamiento para que después, si alguien está interesado, pueda modificarlo a su antojo y hacer así que el script funcione como crea mejor.
En primer lugar como hemos dicho hacemos uso de Tweepy. Así que necesitamos instalarlo. Para hacerlo es muy sencillo, una vez tengamos instalado Python necesitaremos ejecutar el siguiente comando: “pip install tweepy” y listo. No necesita más.
Una vez hecho esto podemos pasar a la creación del script. En nuestro caso fuimos incluyendo un montón de prints para poder ver si estaba recolectando realmente el contenido o no. En esta versión final que os presentamos hemos eliminado muchos de ellos para poder así acortar el código y facilitar su comprensión. No obstante algún print hemos dejado por si fallase el programa en cualquier momento.
Se han añadido comentarios en Español para poder ir viendo lo que hace el script en cada punto y así comprenderse de manera más simple.
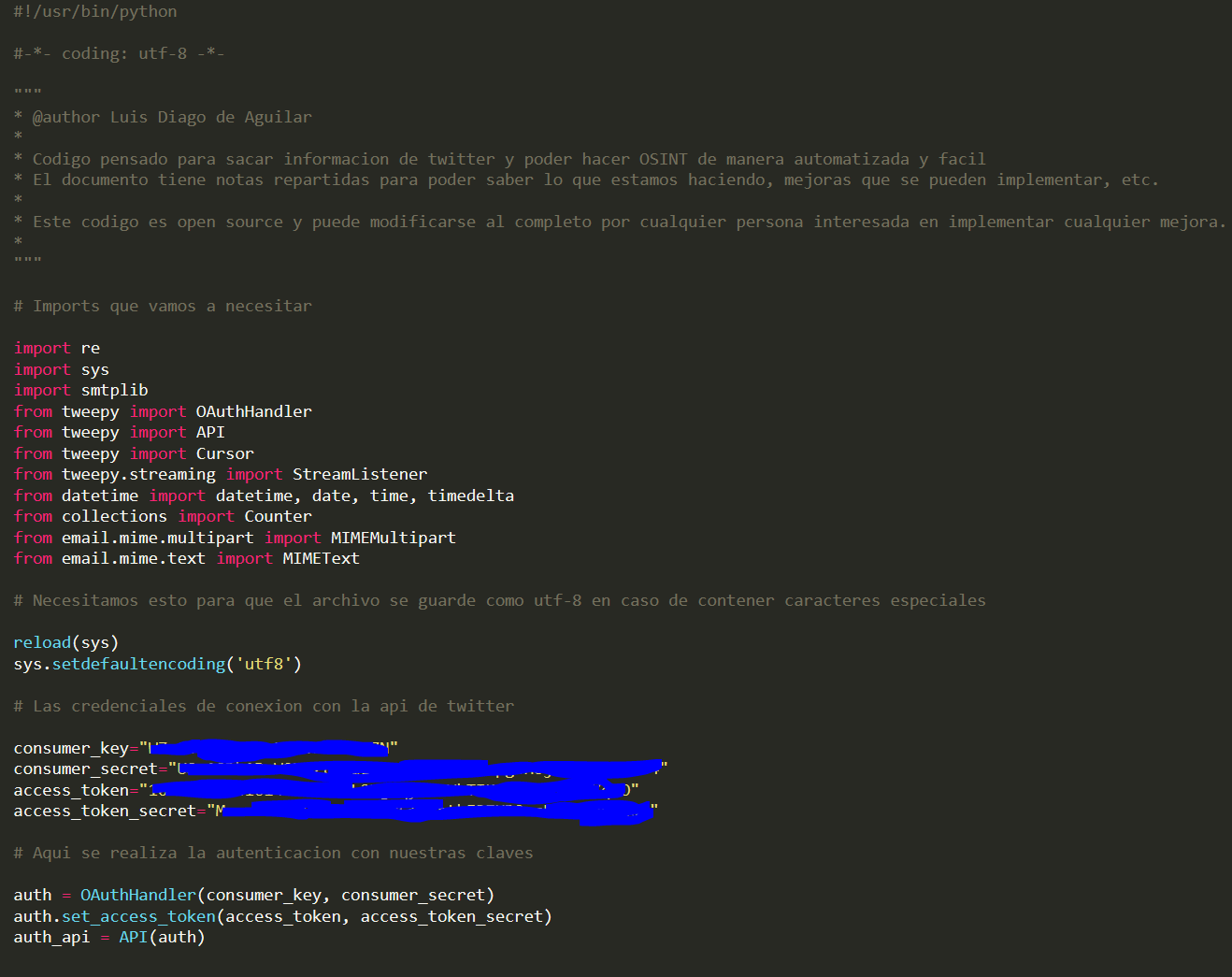
Como puede observarse en la imagen necesitaremos una serie de imports que nos serán de utilidad para el envío del correo, la recolección de la información, etc. Después necesitamos meter las claves de la API de Twitter. Y luego mediante Tweepy realizamos la conexión con nuestra cuenta de Twitter para poder acceder al contenido de la plataforma.
Ahora vamos a ver las diferentes funciones que hemos constituido en Python. La idea es acortar estas funciones en futuras actualizaciones para facilitar los cambios y modificaciones en el script.
El main
La primera de las funciones es el main. En el main lo que haremos será leer un fichero que tenemos asignado, en el cual introducimos con anterioridad las cuentas que queremos monitorizar. Así el programa irá comprobando una por una todas las cuentas.
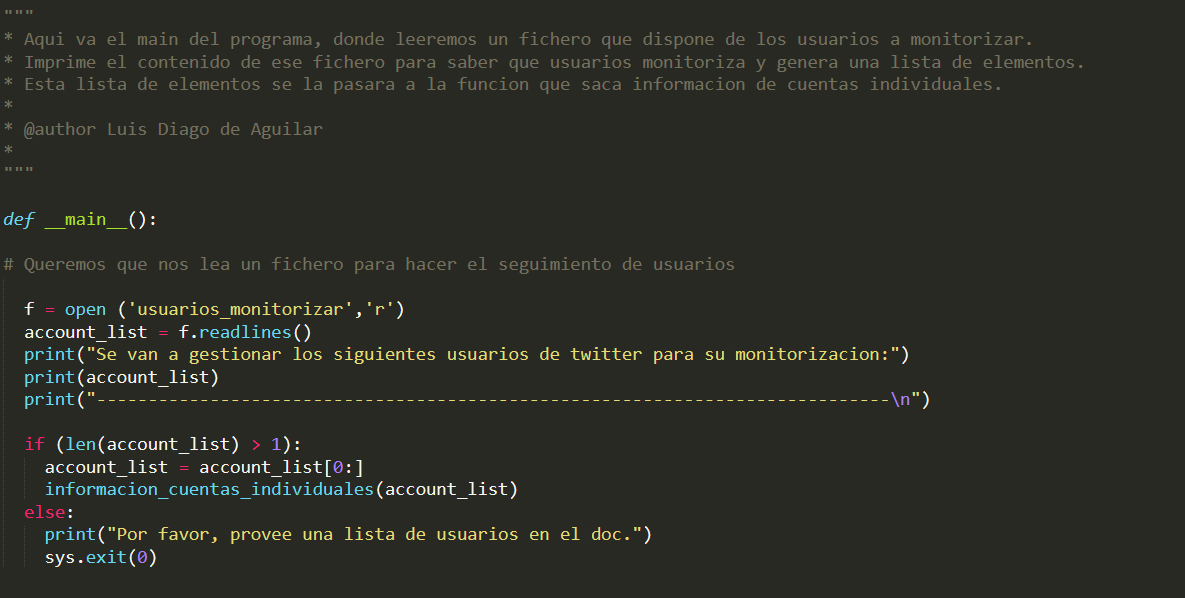
El fichero que lee se denomina en nuestro caso “usuarios_monitorizar”, hemos puesto un print para comprobar que lea bien el fichero. Además guardamos el contenido del mismo en una lista que pasamos posteriormente a la función información_cuentas_individuales(account_list). Si la lista está vacía pedimos que se introduzcan usuarios en el documento.
Escribe fichero, la función que necesitamos para saber si se ha enviado ya o no
Ahora vamos a pasar a la siguiente función que necesitamos tener. Esta función denominada “escribe_fichero”, lo que va a hacer es escribir un fichero con las urls de los tuits. Las urls de los tuits son únicas ya que tienen un id único. Es por ello que al guardarlas podremos luego recurrir a ellas para ver si son repetidas o no.
Ponemos unos prints para ver que todo funciona a la perfección.
La función recibe dos parámetros, el que hemos denominado “texto” porqué será el texto a escribir, y el que hemos denominado “target”, pues queremos que el archivo tenga el nombre del target a monitorizar.
En la función de abrir fichero hemos puesto un “wb+”, esto es porque si el usuario es nuevo a monitorizar y no tiene un fichero creado es necesario que se cree uno nuevo.
Un poco más abajo, leemos el fichero que ya se creó la otra vez o que acabamos de crear, los comparamos, y, si coinciden, no hacemos nada, si no, reescribimos el fichero con la nueva información.
Aquí en vez de reescribirlo podríamos haber añadido las urls a las que ya había, pero, nos ha parecido más eficiente en materia de espacio el simplemente eliminarlas, hay que tener en cuenta que este script está pensado para recopilar mucha información.
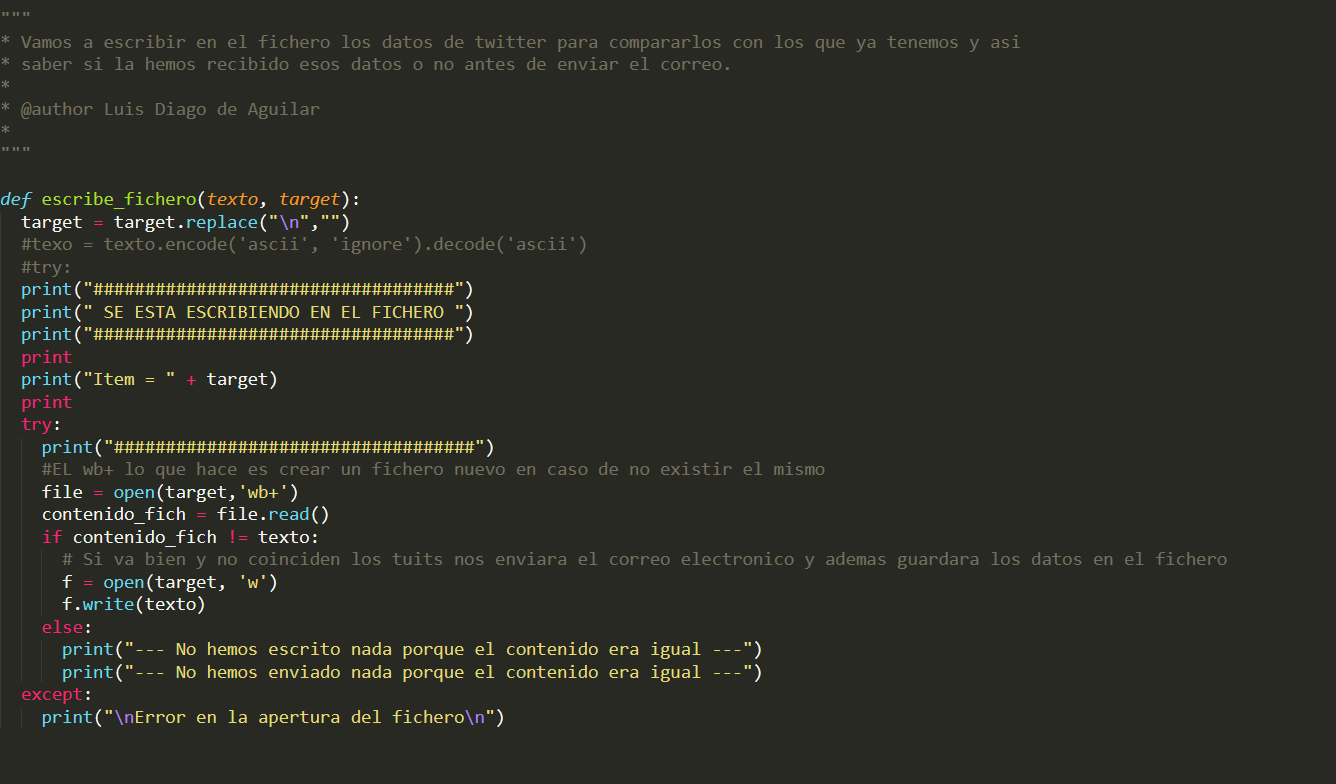
Ponemos un try-except. Esto hace que si da un fallo en la creación o lectura del fichero no se pare el script entero y por tanto la motorización de todos los usuarios.
Nota: observareis que convertimos el target a un target sin el “\n”, justo donde pone target replace. Bien, esto es muy sencillo, de no ser así los ficheros al crearse darían fallo y luego daría problemas a la hora de leerse. Lo usaremos en más ocasiones, como podréis ver más adelante.
Mailer function, la función para enviar los correos
Esta es la función para enviar los correos con la información que queremos. En este caso serán los últimos tuits y alguna que otra info que veremos posteriormente.
En primer lugar como se puede observar le pasamos dos parámetros, el target para que se nos quede guardado el objetivo en el asunto, y el mensaje que vamos a enviar.
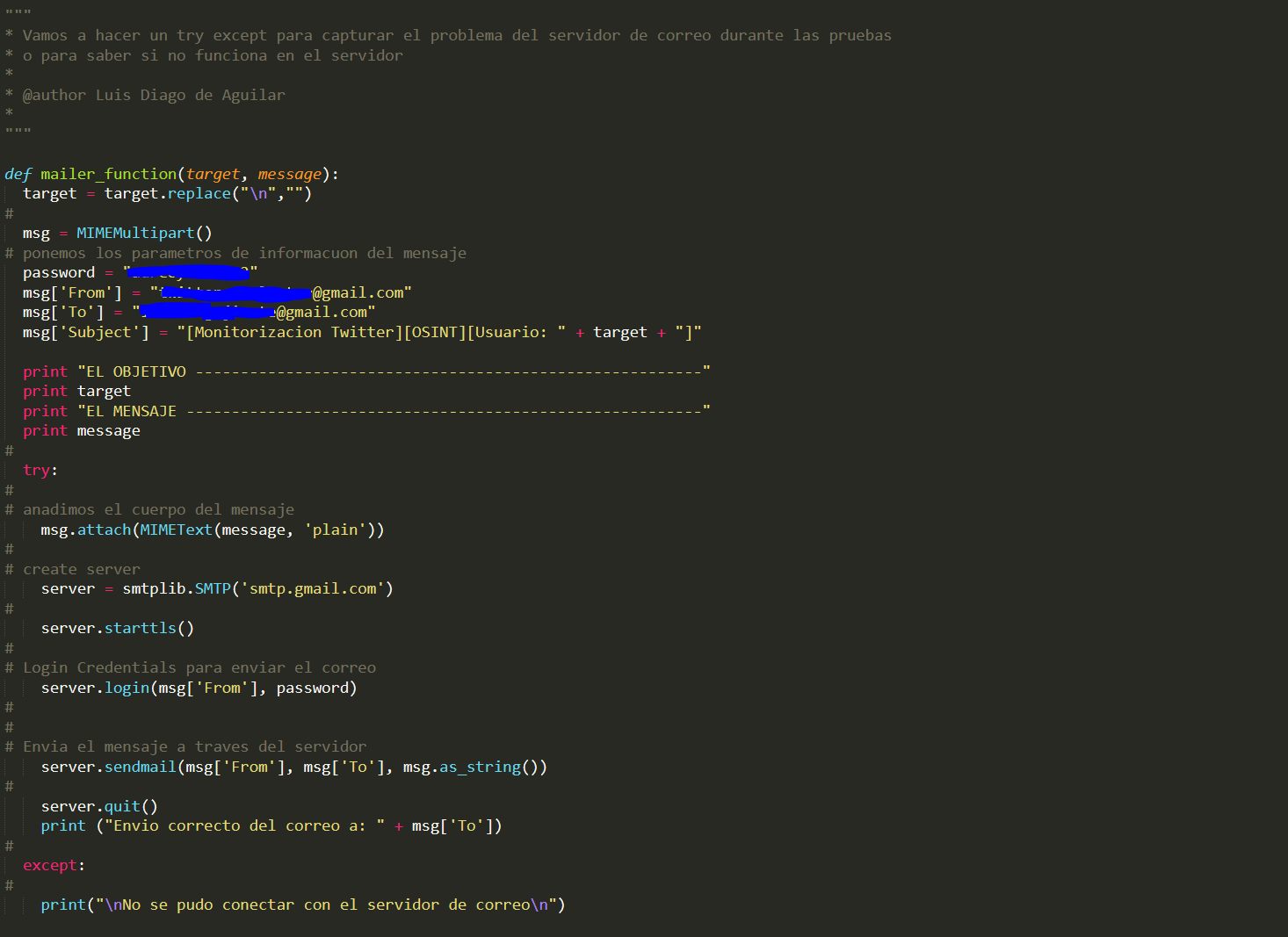
Ponemos nuestras credenciales, y ponemos unos prints para ver que llega bien el mensaje y que no está fallando. Después añadimos un try-except, en caso de no tener el servidor de correo montado durante las pruebas o en caso de fallar la conexión con el servidor, el resto del script seguirá funcionando con normalidad.
Función información cuentas individuales
Esta función recolecta la información que queremos sacar sobre el usuario. Con quién interactúa más, cuales son los hashtags principales que utiliza, etc. Además de los últimos tuits que ha escrito, que es lo que más nos interesa en nuestro caso.
Como vimos en él la función Main, le pasábamos una lista de usuarios que queríamos monitorizar. Con esa lista que le vamos pasando sacamos la información del usuario y vamos añadiendo a la variable message el contenido del mensaje que queremos enviarnos.
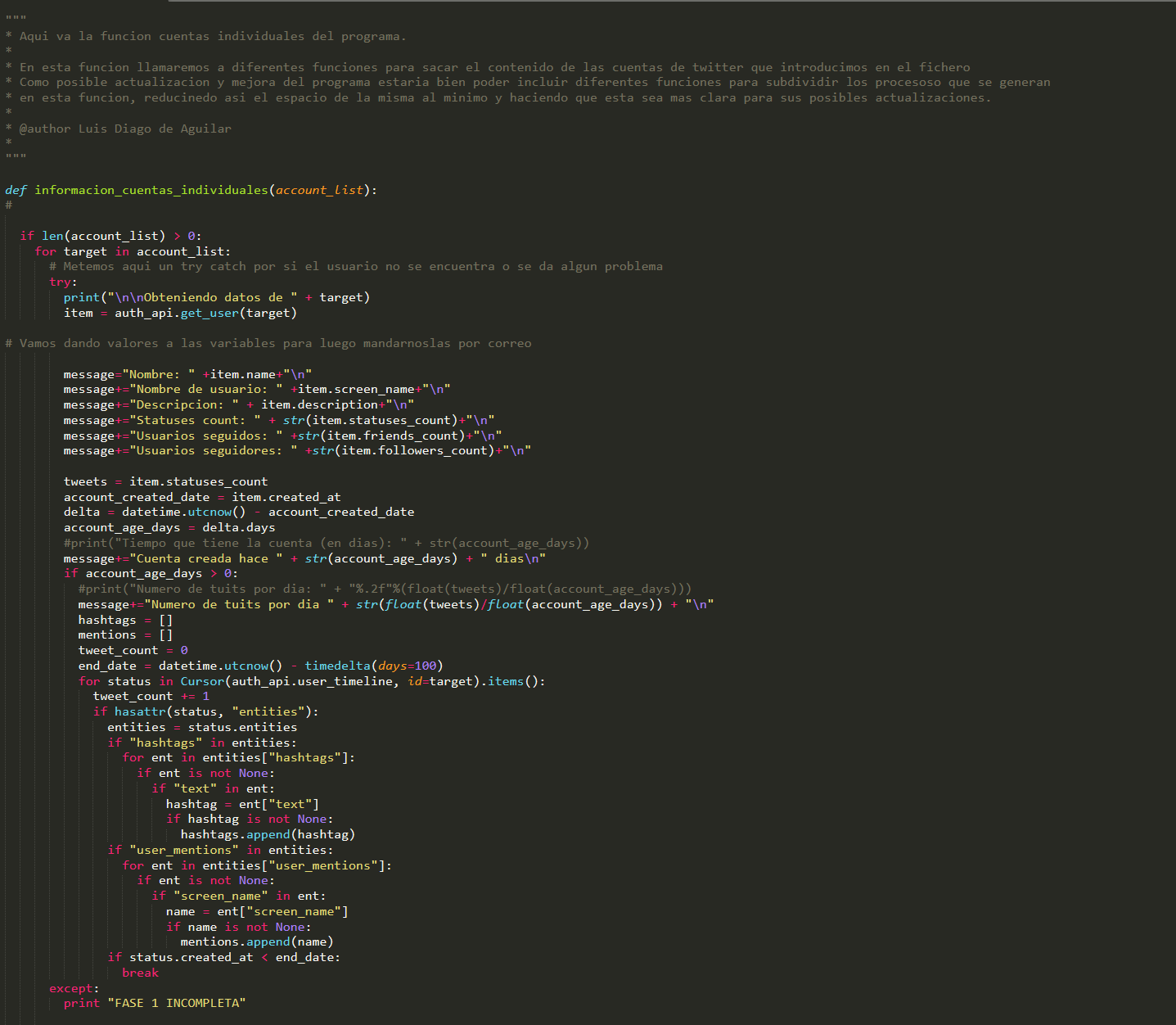
Vamos guardando el nombre de usuario, los hashtags, los usuarios seguidos, la descripción, etc. Y lo hemos dividido en varias fases para que se vea el código entero, puesto que está función es muy larga.
Ahora pasamos a los hashtags que más menciona el usuario y los usuarios que más menciona.
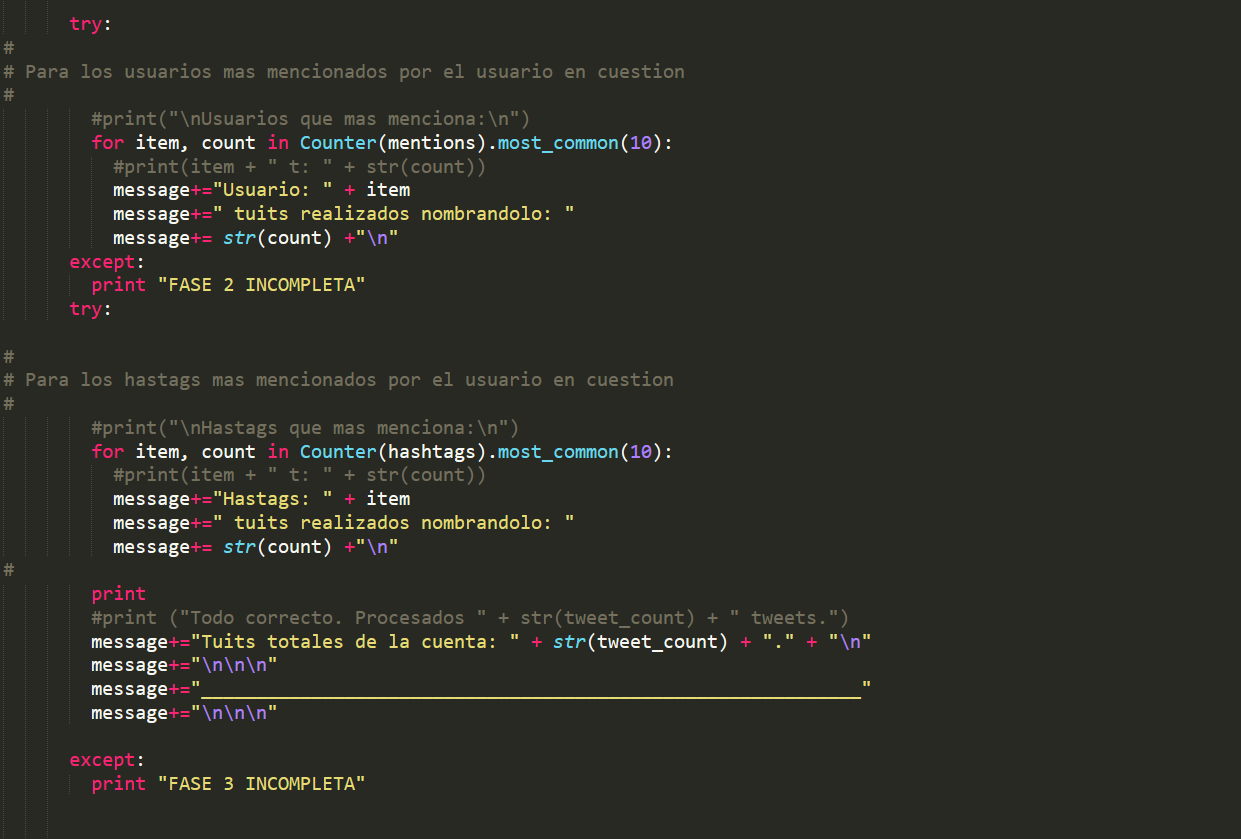
Los try-except se pueden eliminar y unificar en uno solo, pero hemos decidido hacerlo así, para una mayor rapidez en la detección de fallos. No obstante sí que hemos añadido un try-except que engloba casi toda la función ya que ha sido necesario. Si el usuario no existía o estaba bloqueado explotaba el programa. Ahora que está completo y funcional, pasaremos a su eliminación casi con total seguridad, dejando así un solo try-except.
Sacamos los tuits del usuario que luego nos enviaremos
Ahora necesitamos dos variables nuevas “contenido_tweet” y “el_tuit_en_si”. De aquí sacaremos los tuits publicados por este usuario y los guardaremos en la variable el tuit en sí. Además necesitaremos la variable contenido tuit para ver si ya fue listado o no.
Cómo siempre, añadimos unos prints para ver que todo funcione correctamente.
Añadimos el tuit en sí a la variable mensaje y así podremos posteriormente enviar toda la info anterior, más los tuits a nuestro correo.
Guardamos también las urls como decíamos antes en la clase escribe fichero. La comprobación que hacíamos allí para ver si eran iguales o no se puede borrar por qué aquí tenemos nuestra propia comprobación también. Guardamos las urls, si coinciden no hacemos nada, si no coinciden al leer el fichero lo que haremos será guardarlas, de momento en la variable contenido tuit.
Escribimos el fichero y nos enviamos la información
Si la variable contenido tuit tiene contenido significará que hemos conseguido tener información que recolectar y por tanto hacemos el envío del mensaje y la escritura del fichero. Si no es así acabamos la ejecución de las comprobaciones de este usuario y listo.
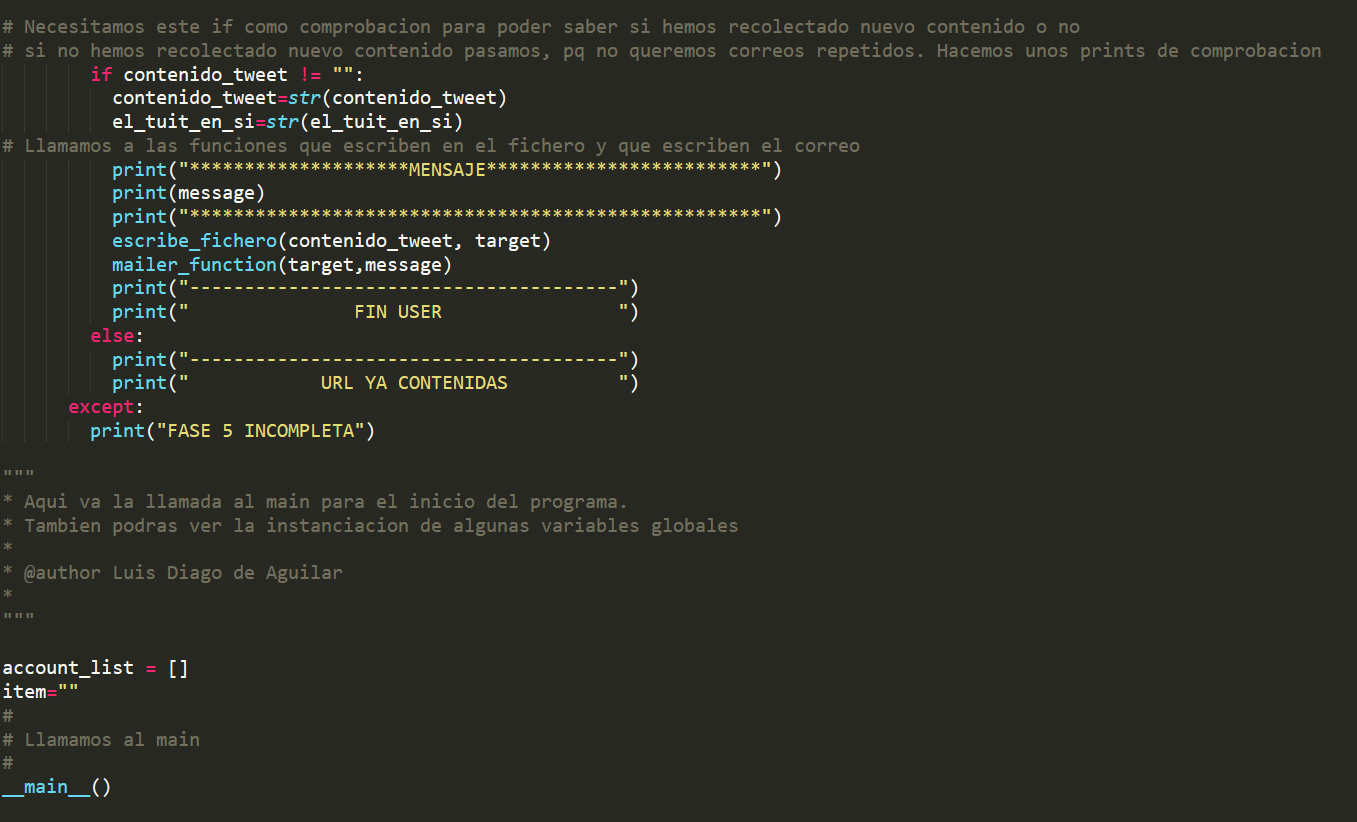
Finalmente creamos las variables globales que hemos estado usando e introducimos la llamada al Main. Así cuando se ejecute el programa comenzará por el Main y seguirá por las funciones a las que vamos llamando en el orden en el que las llamamos.
Resultados del script
Los resultados del script son muy satisfactorios para lo que a nosotros se refiere. Está funcionando perfectamente y la información nos llega cada poco tiempo (esto es gracias a CRON, podéis verlo en el artículo de recolección de información de canales RSS).
Un ejemplo de cómo nos llega el mail sería este (arriba la info de interés que queríamos, abajo los últimos tuits):
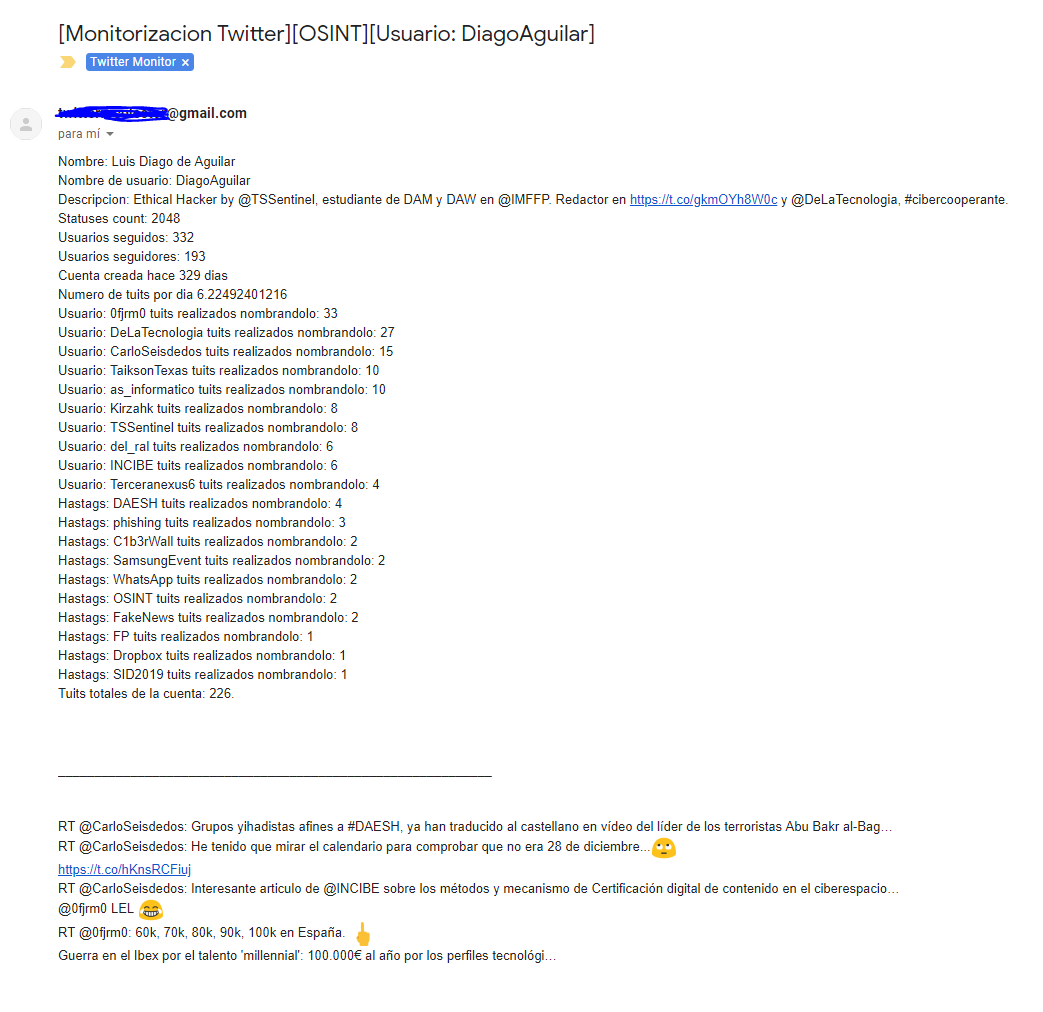
Nota: En la parte que dice tuits realizados nombrándolo se incluyen también los retuits.
Como véis se puede distinguir una línea separatoria entre los tuits y la información de interés. No obstante los tuits no se distinguen muy bien entre sí. Es por ello que añadimos una mejora (añadimos al mensaje 4 guiones “—-“) y ahora tenemos lo siguiente.

Para todos aquellos que estén interesados en el sript, crean que se pueda mejorar o cualquier cuestión no dudéis en dejar vuestro comentario.
Para los que deseen ver el código completo os dejamos aquí el enlace a GitHub.